
Elegance: between complexity and power
The universe of programming contains some helpful concepts that are useful for achieving one of my favorite adjectives: elegance. Elegance, for me, represents a pleasing balance between complexity and power. It’s tempting to go crazy with a feature like Related Entries—but this can increase complexity and make things harder to manage.
In my career, I’m usually building a site for someone else: a marketing team or other group who is producing content using the publishing tools I’m building. Often, we’re not the ones using the CMS; a complex workflow or deeply nested content model can easily confuse the ones doing the publishing.
I find that when it comes to content modeling, it’s best not to over-plan at the beginning, but take a more iterative approach. There are usually some obvious types of things (i.e. entities or content types) that make sense as related types, like blog authors or call-to-action banners. Starting with a basic set of fields and adding on as you go vastly simplifies the work rendering that content in your templating system.
Assessing your content model
Case study: A blog entry
In this example, we examine a blog entry, which has both regular and related fields.
How did we go about deciding which fields to make referenced fields (in bold here), and which to remain as part of the core entry? Reusability, scalability, and development costs are the primary considerations when planning related entries. It’s really tempting to go crazy and add lots of custom fields and related fields. These all come with a cost in development time, tech debt, and content training and management.
Questions I ask myself and the team I’m building the system for:
- How common would this related entry be across all entries of a given type? Of other types? Authors, for example, are a near-universal entity type across blog entries. A related product or service might be fairly rare.
- How unique to this parent entry or type is the proposed related type? Is it going to be used only with say, a blog entry, or is it useful in many places? Quotes were an early entity type that were intended to be associated in lots of places and with many other content types—product pages, customer case studies, etc. I actually got into a bit of trouble with this one when it came to the Customer data model, where Case Study entries contain Customers who contain Quotes… which one gets displayed? It was a bit of a mess on the template side. Don’t be too slick!
A list of our “Metadata bits”
Here’s a few key related entry types that we ended up with and have proven their usefulness:
- Calls to action (CTAs). These can be associated with any entry, and have some complex variable features themselves.
- Forms and Scripts. These are used like CTAs, but for embedding our Hubspot forms (though can be used in other ways too).
- People. These are probably the most heavily-used related content type, and is used for everything from our company leadership directory to customer profiles to guest authors.
- Products/services and features.
- Tags which are used for search and SEO purposes.
- Events are talks, meetups, tradeshows, or webinars.
- Quotes are related to people, customers, landing pages, and even used for press quotes.
Fields used
| Field Name | Type |
|---|---|
| Title | Short text |
| Slug | Short text |
| Publish Date | Date & time |
| Tags | References, many |
| Categories, Blog | Short text |
| Author | Reference |
| Featured Image | Media |
| Social Share Image | Media |
| Summary | Long text |
| Lead | Long text |
| Featured Person | Reference |
| Main Entry | Long text |
| Call to Action | Reference |
| Related Entries | References, many |
| Discovery Topic | Reference |
Bulletproofing your related content
If you relate something, you must consider what that piece of content looks like when rendered. A button? A simple link? A card, with an image preview and other related metadata? What are your fallback and content truncation rules? Some of these problems are managed through content governance, like limiting the length of text fields, or helpful help and error text (all of which happens on the Contentful side, in this case). Other aspects of bulletproofing your related content must happen on the template side. In the process of learning Ruby ERB and now, Slim templating for our Middleman static site, I discovered early on that not checking for the presence of fields would break the entire static site build.
I learned early in my career that content authors cannot see or envision these limitations—they need us to train them and the “system” that we build for them to handle missing fields, too-large images, or content gaps elegantly with a minimum of fuss.

A case study: single-page content app
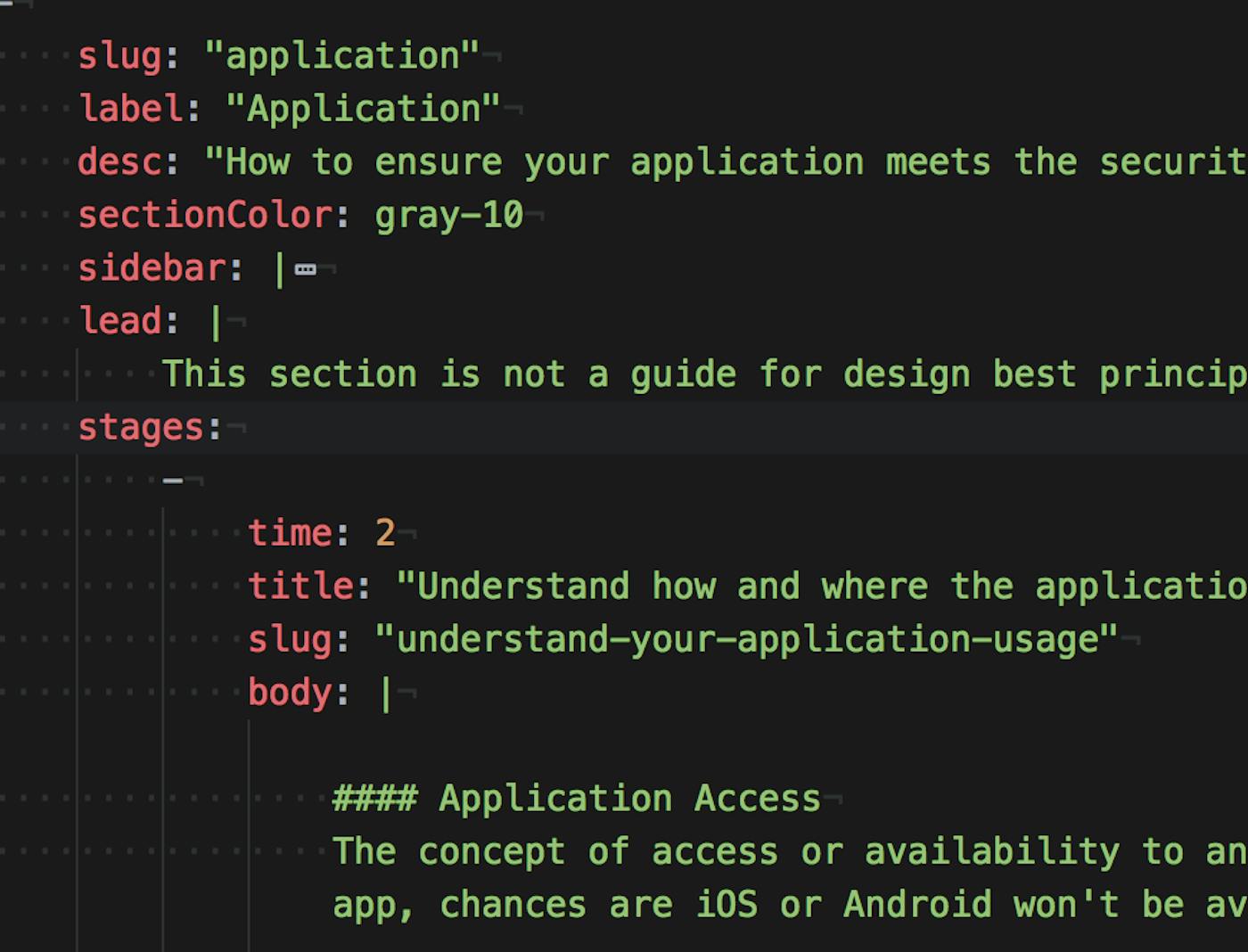
We have some fairly complex data models involving Datica’s Digital Health Success Framework. At launch, the content is managed using hand-written yaml data files. It was such a new concept (layered timelines, complex interactions, lots of little metadata bits on each entry, etc.) that we didn’t know what would be needed at first. It being a new experimental concept also meant we didn’t know if it would take off or not—no sense overbuilding a web product that’s one-and-done.
Complex data-modeling challeges
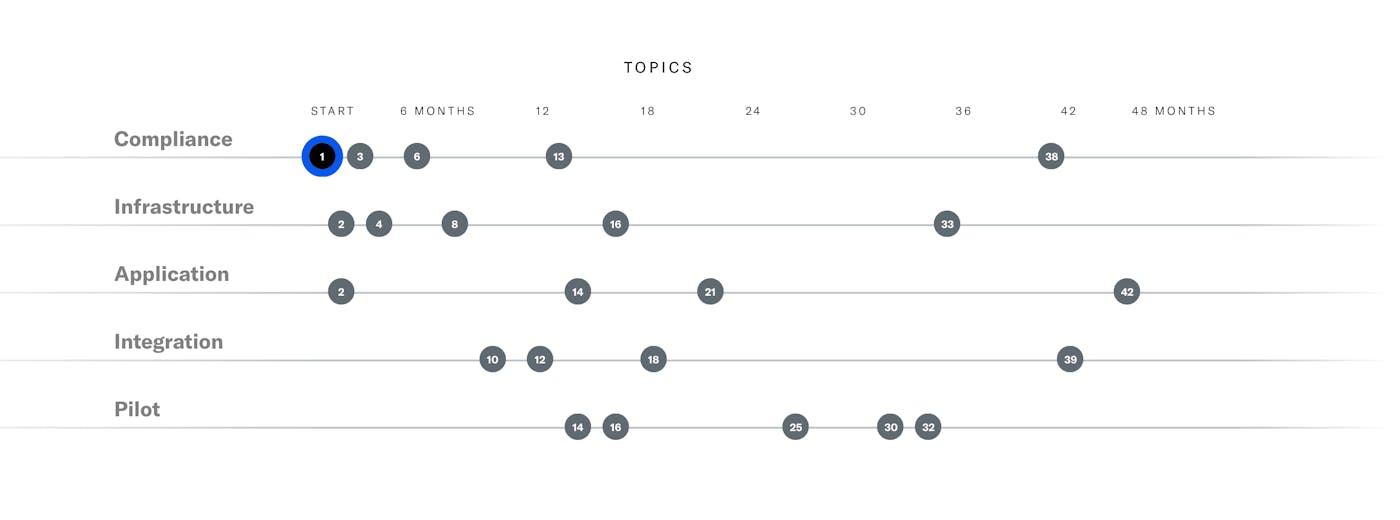
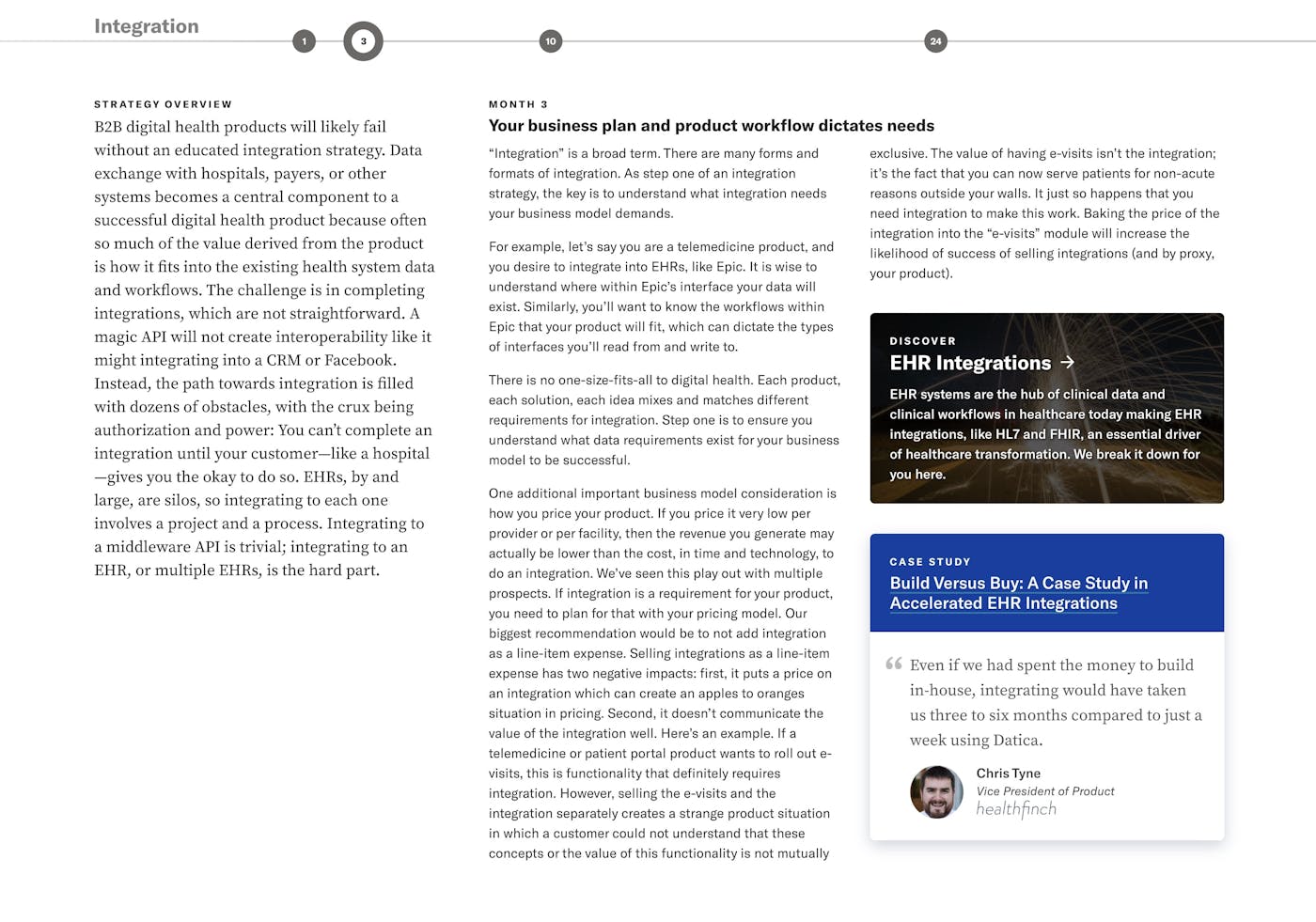
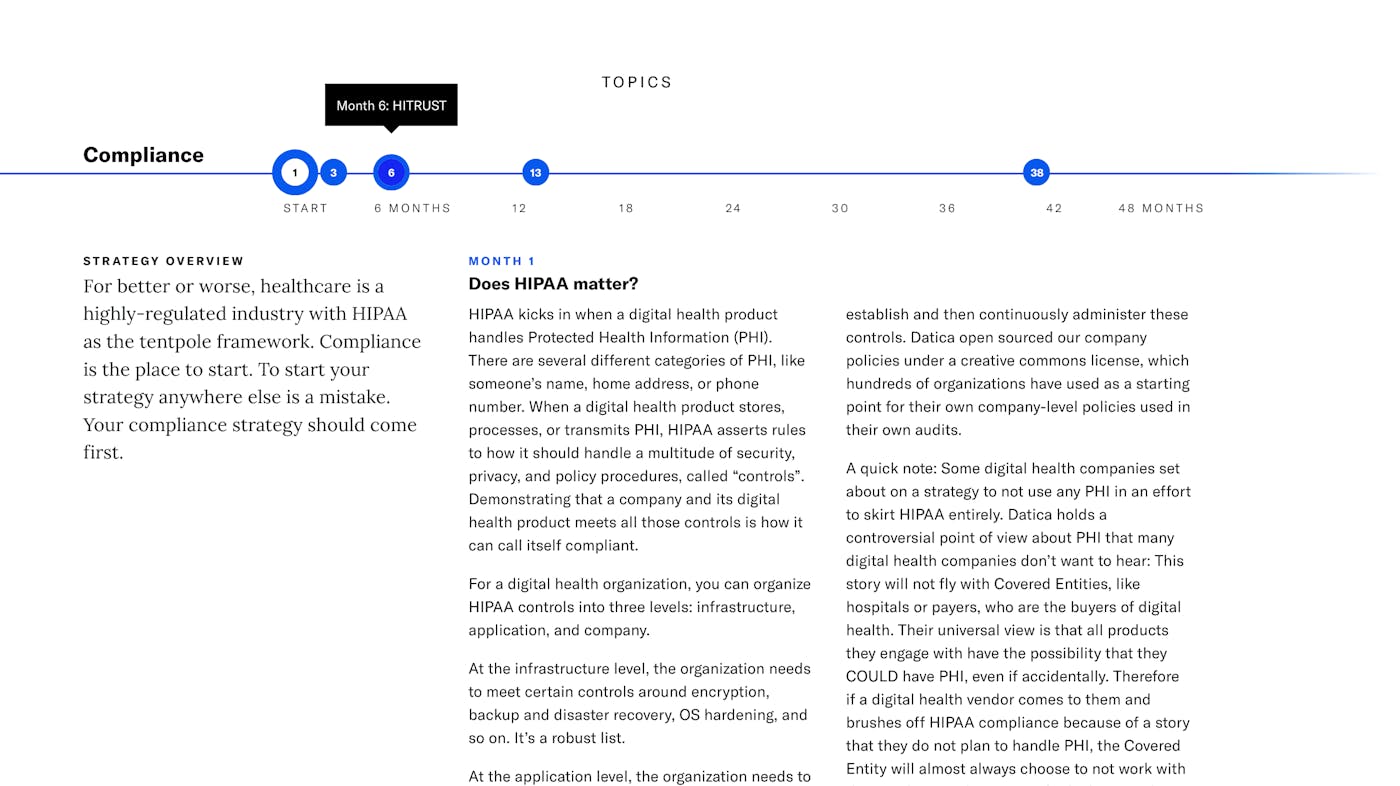
The Digital Health Success Framework (DHSF) is an interactive collection of articles and resources to help early-stage healthcare startups and enterprise innovation teams navigate the requirements and demands of healthcare apps and services.
After a few months, the design & data model iterations had slowed and the data model stabilized. The pace of updates (we added a new layer or dimension, and the time scale changed) also fell into a pattern that we could predict.
Read more about the project here.
Fundamental questions when modeling your content
When evaluating how much effort to put into making content managed in a CMS, I ask questions such as:
- How often will this content need to be added or updated?
- How many different people need to be able to make these changes?
- What skill or subject expertise will authors need?
- How deeply does this content need to be integrated with other content?
This last point is one that can be a real rabbit hole, sucking you into an inception-like world of complexity and frustration. I’ve found it’s not wise to rely on relationships more than one or two levels deep.
After thinking through the example above for a few months, observing our editorial patterns and analytics, I decided it wasn’t worth the effort and complexity to port the data model into our Contentful CMS. The project got done faster and I was able to move on to other projects.
Summary
- Modern CMS systems are incredibly robust and can usually model any kind of data you can imagine. Keep it simple and don’t paint yourself into a corner.
- Know your users: get to know the needs and workflow requirements of the editors who will be using the CMS. Their needs are different than our needs as developers. Is it clear where to edit a thing? Is it tedious? How reusable does an entity really need to be? All of these questions should be handled like you’re doing UX product discovery — just internally.
- Do some solid basic planning, prototype, iterate quickly, and then add complexity carefully. Rely on related content types only for items your editors really, really need to re-use.